
Dig deeper into GDB’s data: Hello, world! — Part 1
If you are reading this, we hope for the following things: first, that you are as excited as we are for the release of the results and data undertaken by the Global Data Barometer project to understand the state of data for public good around the world. Second, that you have browsed our website to see the initial trends to understand it. Third, that this is simply not enough for you, so your enthusiasm to go beyond the summarised data published on the website has led you here, reading more about how you can explore data in a more granular level, because you think, just as we do, that rankings and overall scores are only one approach to data. And the final and fourth thing we are hoping is that you are now ready to become best friends with the Barometer’s data.
Before you go off on your own and find new data insights, first familarize yourself with The Barometer’s methods, which you can learn about in more detail in the “Research section” of GDB’s website. Then, you should also familiarize yourself with the overall structure of the released database, which can be found in the “Results“ page.
In this blog series, we will share guidelines that can get you started on specific indicators and tackle more granular variables within the Barometer.
Meet GDB data
The Barometer is built from 39 primary indicators and 14 secondary ones. In this post series we will focus on primary indicators, which have more rich and complete information, since the evidence to get to the score was collected through an expert survey by the GDB research network, composed of 12 regional hubs, 113 national researchers and 6 thematic partners.
Above, below and within the indicators
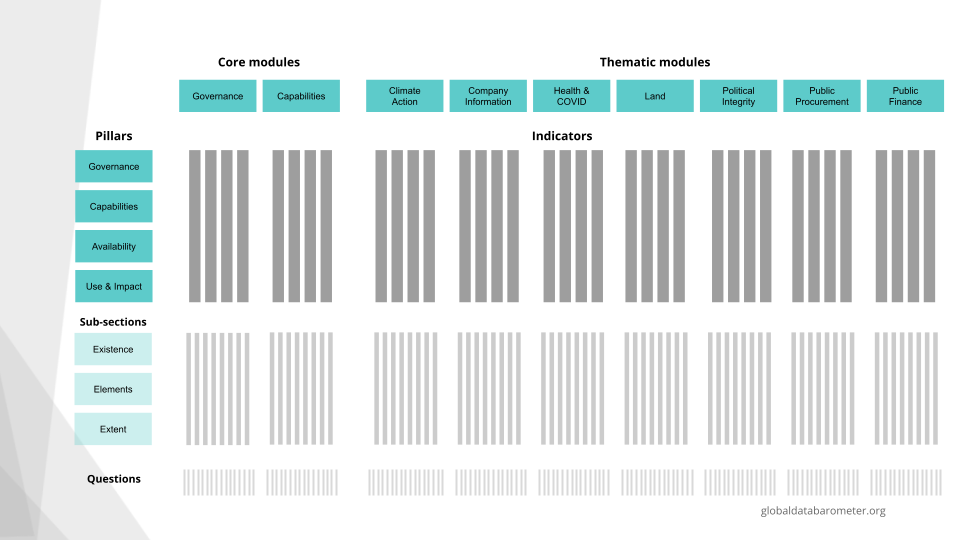
Indicators and the Barometer’s structure
Each indicator informs one of the main four pillars of the GDB (i.e. data governance, data availability, data capabilities or data use and impact). At the same time, each indicator belongs to a GDB module. There are two core modules, in coincidence with two of the pillars, (i.e. Governance and Capabilities) which captures information at a general countrydata level. Then there are seven thematic modules (e.g. Climate Action or Public Procurement), which analyzes data through specific thematic lenses so that we can understand how data is managed and deployed for public good in these specific areas.
For starters, let’s work with an indicator that belongs to the Public Finance module, and informs the pillar of Data Availability. The indicator “Availability for budget and spending data” explores to what extent a particular government budget and spending information (budget execution) is available as structured open data.
Primary indicators also share the same structure. A straightforward way to approach GDB data through the database (see database schema in our Open Data section) is to use the hierarchy levels (‘hierarchy_level’ field in the database) as a guide. Indicators are variables at the level 1. At each level, researchers provide different kinds of information (‘data_type’). In this first level, the type of information provided could be a general justification or sources of evidence (files or URLs with main sources of the assessment). The score assigned to an indicator is calculated from the answers at the subquestion level, which is the 4th one, and that we will explain later.
Above the indicators, in the Barometer’s database you can find information and scores at an overall GDB level, and at pillars and modules level, which are all level 0.
Indicators’ sub-components
Below the indicators, we can find information on variables within indicators. The next level is number 2, which are the sub-sections of the indicators:
- Existence, assessing whether relevant frameworks, institutions, training programs, datasets, or use cases exist, and the nature of its existence
- Elements, which perform a detailed and structured assessment on the frameworks, datasets, capabilities or use cases found.
- Extent, exploring whether what is being evaluated demonstrates comprehensive coverage or whether it has limitations.
These sub-sections are also important because the overall score of an indicator is built from the interaction between them: each element has a fixed weight and all the elements inside an indicator sum up to 100 points. To find out more about the scores calculation, please read the methodology section in the Report.
Then according to the answers provided in Existence and Extent, that Elements score is multiplied by a value between 0 and 1. In an indicator that belongs to the Availability pillar, for example, if in the Existence sub-question it is assigned the top scoring value, “Data is available from government, or because of government actions”, the multiplier assigned to the Existence sub-section will be 1, so there will be no modifications to the score from the Elements. But if the answer was that data is available, but not as a result of government action, then the score in Elements will be multiplied by 0.5. A similar process occurs with the Extent questions.
The next level of disaggregation of an indicator is the third, which are the sub-groups of Elements, since the detailed assessment of evidence for each indicator shares common aspects, such as assessing data fields and quality issues or openness and timeliness matters. The elements inside the openness subgroup are all the same in indicators that belong to the same pillar, and were chosen inspired by the Open Definition, which sets that a dataset “is open if anyone is free to access, use, modify, and share it — subject, at most, to measures that preserve provenance and openness”. In practice, this translates into the data being available in a digital, machine-readable and non-proprietary form, either free or at no more than the cost of reproduction, and under explicit terms that permit re-use (rather than restrictive copyright terms for example). The central idea of the Open Definition is that, when technical or legal barriers (either explicitly, or as a result of uncertainty) to re-use are removed, data can be put to much wider use. The Elements on data fields and quality sub-group vary according to the kind of datasets of frameworks assessed, for example and were built upon international agreements or shared practices.
Apart from the information provided at an indicator level (justifications and sources of evidence), national researchers did not work directly with variables from level 0 to 3, whose scores are calculated based on the answers provided by researchers at the fourth level, which are the sub-questions. At this level, you will find a lot of information about the survey and the researchers’ responses. In the field “question” you will find the exact question or statement showed to the researcher, for example: “There is structured data about the government’s extrabudgetary funds spending, in gross terms and on an accrual basis”, to which the researcher could answer “yes”, “partially”, or “no”, answer stored in the “response” field. According to the answer, there was a supplementary question, which belongs to the same variable, but has a different data type. If the former was a “response” data type, this latter is indicated as a “supporting”, which is not a structured one, but which asks for further explanations and precise evidence used to answer that sub-question. For example, a supporting question may ask for a specific URL where to find that data, or the format in which a dataset is released.
What have we learnt
We would be happy to hear if you have a better understanding of the Barometer’s structure. We hope you have a clearer idea as to how you can use the data to dig deeper and inquire further. Stay tuned for part 2 of this blog series, if that’s not yet the case. We will continue to show you how you can work with the Barometer’s data. But if you are you ready, start here!